InstructPix2Pix: Learning to Follow Image Editing Instructions
InstructPix2Pix
Abstract

∘ image와 instruction(ex. "Swap sunflowers with roses") 입력→ edited image
∘ language model(GPT-3)과 text-to-image model(Stable Diffusion)로 생성한 image editing example dataset으로 학습
∘ edit에 걸리는 시간이 짧음
- forward pass에서 edit 진행
- example마다 이루어지는 fine-tuning, inversion이 없음
1. Introduction
∘ 생성 모델이 사람이 작성한 image editing instruction을 따르도록 학습시키는 방법에 관한 연구
∘ 서로 다른 modality를 가진 LLM(GPT-3)과 text-to-image model(Stable Diffusion)을 위한 paired dataset 생성
InstructPix2Pix는
∘ forward pass에서 edit 진행
∘ 추가적인 예시 이미지, 입/출력 이미지에 대한 전체적인 묘사, 각 example에 대한 finetuning을 필요로 하지 않음
∘ 실사 이미지와 사람이 작성한 instruction에 대해 zero-shot 일반화 가능
∘ 직관적인 edit 수행 가능
2. Prior work
Composing large pretrained models
∘ multimodal task 수행을 위해 큰 규모의 pretrained model들을 결합해 이용
∘ pretrained model 결합을 위한 기술
- joint finetuning
- 프롬프팅을 통한 communication
- energy-based models의 확률 분포 조합
- 다른 모델의 피드백으로부터 얻은 guide 이용
- 반복적인 최적화
∘ 기존 연구와 달리 mult-modal pair로 된 training data를 사용
Diffusion-based generative models
∘ diffusion model의 발전 ⇒ SOTA 이미지 합성 기술, 다른 modality의 생성 모델
Generative models for image editing
∘ 과거 : 다수의 image editing model들은 image를 latent space로 옮겨 latent vector를 edit
↔ 현재 : CLIP 임베딩을 이용해 텍스트로 image editing guide ex. Text2Live
∘ 몇몇 text-to-image model은 자체적으로 image edit이 가능하지만 비슷한 text가 비슷한 이미지를 생성할 것이라 확신 불가하다는 문제가 존재
→ Prompt-to-Prompt로 해결. 유사한 text prompt로 생성된 이미지들을 동화시킴.
⇒ 생성된 이미지에 대해 독립적인 edit 적용 가능
∘ SDEdit는 생성되지 이미지(= 실제 이미지)를 edit 하기 위해 pretrained model을 이용해 새 target 프롬프트로 input image에 대해 noise를 가하고 제거
Learning to follow instructions
∘ 기존 모델 : input/output image에 대한 설명 입력
↔ InstructPix2Pix : 모델이 취해야 할 action의 instruction을 입력. 자연어로 지시 가능. 추가적인 정도 제공 필요 없음. instruction의 이점을 가짐.
Training data generation with generative models
∘ 인터넷 데이터로부터 딱 필요로 하는 형태, 특히 지도 학습을 위한 형태의 데이터를 찾아내기 어려움
∘ 생성 모델이 발전함에 따라 training data를 위한 저렴하고 풍부한 자원으로서 각광받음
3. Method
∘ instruction 기반 image editing은 지도학습으로 학습시킴

∘ text editing instruction과 before/after image들의 pair로 이루어진 training data 생성
∘ GPT-3가 edit instruction과 edited caption 생성
∘ Stable Diffusion : real image 생성
∘ Prompt2Prompt : 유사한 text 입력 시 유사한 image가 출력되도록 학습된 모델

∘ 위 과정으로 생성한 training data로 모델 학습
∘ 모델에 의해 생성된 image들과 instruction으로 학습되었음에도 불구하고 real image와 사람이 작성한 instruction에도 일반화되어 결과를 낼 수 있음
3.1. Generating a Multi-modal Training Dataset
∘ 서로 다른 modality를 처리하는 두 pretrained model들을 결합하므로 multi-modal training dataset 필요
3.1.1 Generating Instructions and Paired Captions
∘ text edit collection 생성 필요
∘ image를 설명하는 prompt(= image caption)를 입력 → image에 가할 변화(= editing instruction), 변화가 가해진 image를 설명하는 prompt(=resulting/edited text caption) 생성
∘ data set 항목 : input caption, edit instruction, output caption
∘ LAION-Aesthetics dataset에서 700개의 input caption 샘플링 후 input, output caption 작성
∘ GPT-3 Davinci model 학습 시 single epoch, parameter 기본값 설정
∘ LAION-Aesthetics dataset에 일부 비합리적인, 설명이 부족한 caption 존재 ⇒ classifier-free guidance로 noise 완화
3.1.2 Generating Paired Images from Paired Captions
∘ paired caption text가 pretrained text-to-image model를 거쳐 paired image가 출력되는 과정에서 model이 image 일관성을 보장하지 않는다는 문제 존재
⇒ Prompt-to-Prompt 이용. 몇몇 denoising 단계에서 cross attention weight를 공유함으로써 해결.
∘ edit 종류에 따라 image-space에서의 변화의 크기가 다름
⇒ 'CLIP space에서의 두 이미지 사이의 변화'와 '이미지 캡션 pair 사이의 변화'의 일관성을 측정함으로써 Prompt-to-Prompt 모델과 Stable Diffusion의 실패의 영향을 감소시킴
3.2. InstructPix2Pix
∘ written instruction에 따라 image를 edit하는 conditional diffusion model의 학습을 위해 이 과정을 통해 생성된 training dataset을 활용
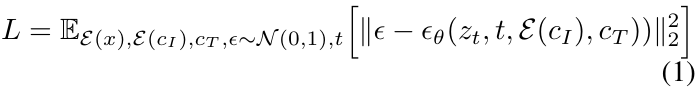
∘ image translation task에 있어서는 finetuning 한 큰 규모의 image diffusion 모델의 성능이 처음부터 학습시킨 모델보다 좋음. 특히 training data 부족 시.
∘ 높은 수준의 text-to-image 능력을 위해 pretrained Stable Diffusion 모델의 parameter 값들을 참고하여 weight의 초기값 설정
3.2.1 Classifier-free Guidance for Two Conditionings
∘ diffusion model로 생성된 샘플들의 품질과 다양성 사이의 균형을 맞추는 역할
∘ 시각적 품질 향상
∘ sample이 조건에 더 알맞게 대응되도록 함
∘ class-conditional, text-conditional image 생성에 자주 이용됨
∘ implicit classifier p(c | z_t)가 c에서 가장 큰 확률값을 가지도록 확률 mass를 shift시킴
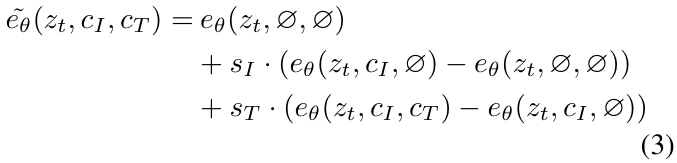
∘ conditional, unconditional denoising에 대해 같이 모델 학습 수행 후 추론 단계에서 두 평가 추정치를 합침
4. Results
∘ 도전적인 edit의 성공적인 수행 결과를 보임
- 사물 변경, 계절 및 날씨 변경, 배경 변경, 재질 변경, 예술 매체 변환 등의 edit
4.1. Baseline comparisons
∘ SDEdit : pretrained diffusion model을 이용하여 부분적으로 노이즈가 있는 image를 입력 받아 노이즈 제거하여 새로운 edited 이미지 생성
∘ Text2Live : 색상, 불투명도 증강 layer를 생성함으로써 text prompt에 부합하는 image edit을 하는 기술
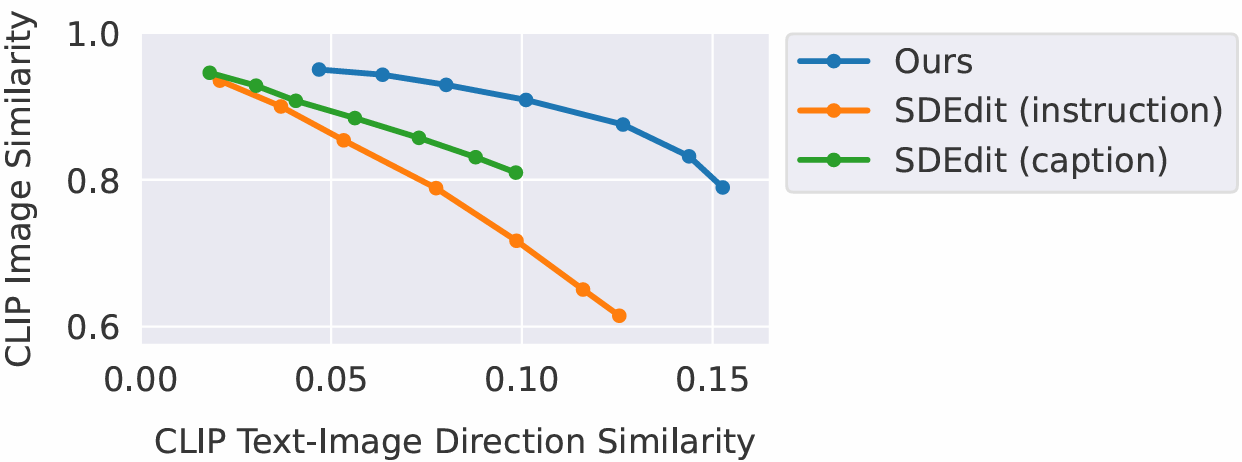
∘ 값이 높을수록 좋은 image similarity, text-image direction similarity 항목에서 InstructPix2Pix에서 측정된 값이 나머지 모델들의 값보다 큼

∘
4.2. Ablations
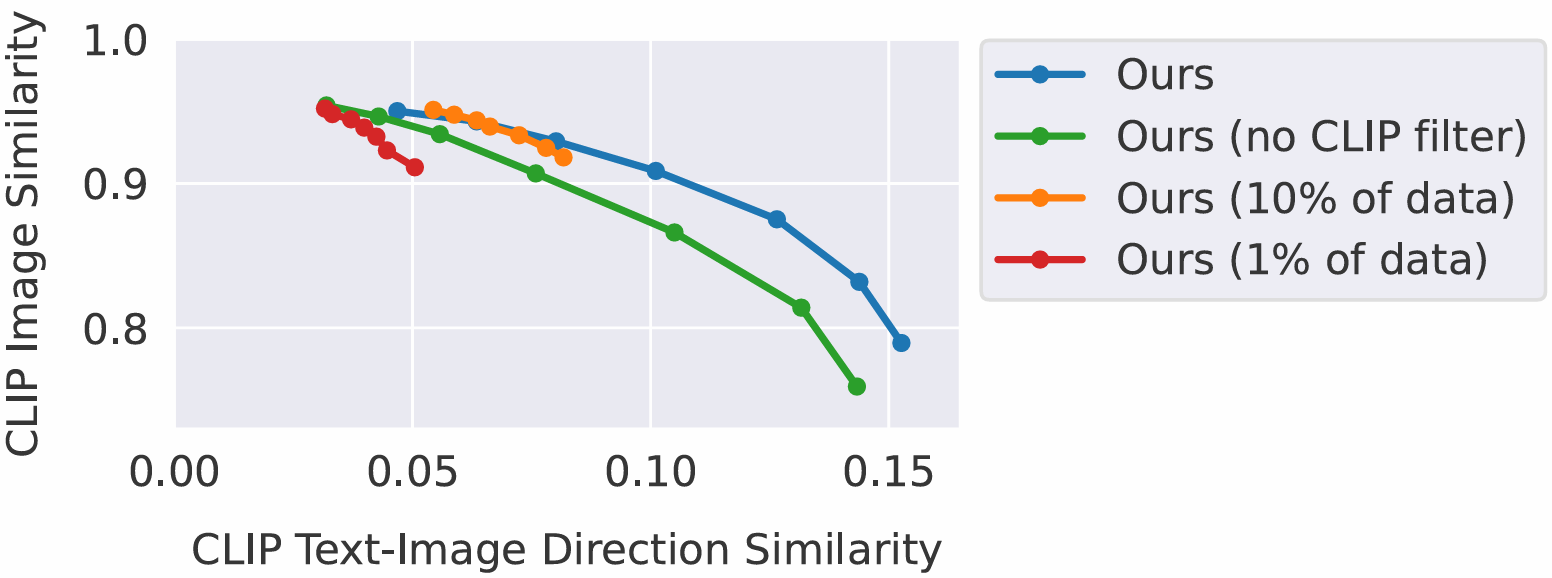
∘ 데이터셋 크기에 따른 결과 비교 결과, 가하는 변화의 규모가 작은 edit만 수행됨
∘ 데이터셋 생성 단계에서의 CLIP 필터링을 제거하면, input image와 전제척인 image의 일관성 감소
∘ S_I와 S_T 값의 증감에 따라 classifier-free guidance가 주는 영향이 달라짐
5. Discussion
∘ 생성된 dataset의 시각적 품질에 의해 제한됨
∘ 새로운 edit의 일반화 능력, 시각적 변경과 text instruction 간의 적절한 연관을 만드는 능력이 GPT-3의 finetuning에 사용되는 사람이 작성한 instruction들, GPT-3의 instruction 생성과 caption 수정 능력, Prompt-to-Prompt의 생성된 이미지를 수정하는 능력에 의해 제한됨
∘ 이 모델은 개수를 세는 수행, 공간과 관련된 수행에 취약함
* modality : 입력 데이터의 종류 또는 유형
* diffusion model
* Stable Diffusion : 텍스트, 이미지 프롬프트에서 독특한 실사 이미지를 생성하는 모델
* downstream task : pretrain 이후 finetuning을 함으로써 이루고자 하는 최종 task
* checkpoing : parameter 값들을 포함하여 저장된 모델 정보
* ablation : 특정 알고리즘/모델을 적용/제거했을 때의 성능을 비교하는 연구
참고)
[논문리뷰] Prompt-to-Prompt Image Editing with Cross Attention Control
MathJax = { tex: {inlineMath: [['$', '$'], ['\\(', '\\)']]} }; Prompt-to-Prompt Image Editing with Cross Attention ControlAmir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, Daniel Cohen-Or[paper] [github]Contents1. Introduction2. Method3. Ap
kkm0476.tistory.com
https://process-mining.tistory.com/182
Diffusion model 설명 (Diffusion model이란? Diffusion model 증명)
Diffusion model은 데이터를 만들어내는 deep generative model 중 하나로, data로부터 noise를 조금씩 더해가면서 data를 완전한 noise로 만드는 forward process(diffusion process)와 이와 반대로 noise로부터 조금씩 복
process-mining.tistory.com